The Pipeline Analogy
XML1 → XInclude → XML2, XSL → XSLT → XML3
If you think of the steps as physical boxes and the connections between them as actual pipes, you can imagine water flowing through the boxes:
 |
W3C XML Processing Model Working Group started in late 2005.
Many familiar names: Erik Bruchez, Andrew Fang, Paul Grosso, Rui Lopes, Murray Maloney, Alex Milowski, Michael Sperberg-McQueen, Jeni Tennison, Henry Thompson, Richard Tobin, Alessandro Vernet, Norman Walsh (Chair), Mohamed Zergaoui
According to its charter, the goals of the XML Processing Model Working Group are to develop two Recommendation Track documents:
An XML Processing Language (XProc)
An XML Processing Model which defines or describes the default processing for an XML document.
I thought we'd finish before our charter expired on 31 Oct 2007 :-)
But we didn't :-(
But we did get to Last Call :-)
But it didn't stick :-(
Latest draft published on 29 November 2007 :-)
I think we'll finish this winter/spring :-)
A defaulting story for syntactic simplicity
A revised mechanism for dealing with parameters
A mechanism for dealing with complex namespace issues
Support for XPath 1.0 and XPath 2.0
A revised approach to XSLT
A few new steps
From XML Processing Model Requirements and Use Cases:
Start with a document or documents
Apply one or more processes, perhaps conditionally, perhaps iteratively
Catch and recover from errors, if they occur
Produce a document or documents
Well, yes: Apache Ant, Cocoon Sitemaps, GNU JAXP Library: Package gnu.xml.pipeline, Jelly : Executable XML, MT Pipeline Overview, NetKernel - Service Oriented MicroKernel and XML Application Server, Oracle XML Developer's Kit Home, Re-Interpreting the XML Pipeline Note: Adding Streaming and On-Demand Invocation, Schemachine (a pipelined Xml validation framework), ServingXML, smallx: Project Home Page, Strawman: bringing the framework within the schemas, SXPipe: Simple XML Pipelines, Xerces Native Interface, XML-ECHO, XML Pipeline Definition Language Version 1.0, XML Pipeline Language (XPL) Version 1.0 (Draft), XPipe
Standardization, not design by committee
Able to support a wide variety of steps
Prepared quickly
Few optional features
Relatively declarative
Amenable to streaming
“The simplest thing that will get the job done.”
Pipelines are composed of steps; steps perform specific processes
Steps are connected together so the output of one step can be consumed by another
Steps may have options and parameters
XPath expressions are used to compute option and parameter values, identify documents or portions of documents to process, and to select what steps are performed.
Most steps are atomic, black boxes that perform a task:
Document1 → XInclude → Document2
Load → Document
Document1, Stylesheet → XSLT 1.0 → Document2
Documentsi…k, Stylesheet → XSLT 2.0 → Documentsm…n
Document → Render-to-PDF
Document1, Document2 → Compare → Document3
XML1 → XInclude → XML2, XSL → XSLT → XML3
If you think of the steps as physical boxes and the connections between them as actual pipes, you can imagine water flowing through the boxes:
|
The “water” of our pipelines are XML documents.
In the specific case of XProc, we mean documents conceptually:
Not SAX events or StAX streams
Not DOM elements or XOM nodes
Not XDMs or PSVIs
(or rather, any of those.)
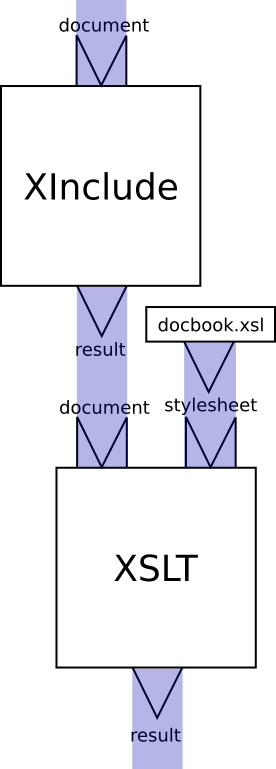
Consider the XInclude+XSLT steps from the earlier slide:
→ XInclude → XML2, XSL → XSLT →
You can construct a pipeline that performs these steps:
→ XInclude → XML2, XSL → XSLT →
Some steps contain other steps, the task they perform is at least partly determined by the steps they contain.
These steps provide the basic control structures of XProc:
Grouping
Conditional evaluation
Exception handling
Iteration
Selective processing
Pipelines
Pipelines can be called as atomic steps:
Document1 → XInclude+XSLT → Document2
Steps have a type and a name (for example, an “XSLT” step named “db2html”)
Steps have named ports
The names of the ports on any given step are a fixed part of its signature (the XSLT step has two input ports, “source” and “stylesheet” and two output ports “result” and “secondary”)
Inputs and outputs bind document streams to ports (the “stylesheet” input port of the “db2html” step is bound to a particular document).
In a pipeline document, the step element identifies the type of the step. The name attribute provides its name (<p:xslt name="db2html">)
Inputs and output bindings are associated with a particular port with the p:input and p:output elements
The p:pipe element provides a binding to another step
The p:document element provides a binding to a particular URI
The p:declare-step element defines the signature for an atomic step.
1 <p:declare-step type="p:xinclude"> 2 <p:input port="source"/> <p:output port="result"/> 4 <p:option name="fixup-xml-base" value="false"/> <p:option name="fixup-xml-lang" value="false"/> 6 </p:declare-step>
The XProc specification includes the declarations for all the standard components. Implementors can provide additional steps and may provide facilities that allow users to write their own.
1 <p:xinclude name="expand"> 2 <p:input port="source">…</p:input> </p:xinclude> 4 <p:xslt name="db2html"> 6 <p:input port="source"> <p:pipe step="expand" port="result"/> 8 </p:input> <p:input port="stylesheet"> 10 <p:document href="docbook.xsl"/> </p:input> 12 </p:xslt>
Many pipelines are linear or mostly linear.
Many steps have a pretty obvious “primary” input and “primary” output
Taken together, these to observations allow us to introduce a simple syntactic shortcut: in two adjacent steps, in the absence of an explicit binding, the primary output of the first step is automatically connected to any unbound input(s) of the second.
(In fact, the specification goes a little further, providing the concept of a default readable port.)
1 <p:xinclude name="expand"/> 2 <p:xslt name="db2html"> 4 <p:input port="stylesheet"> <p:document href="docbook.xsl"/> 6 </p:input> </p:xslt>
1 <p:xslt name="db2html" version="2.0"> 2 <p:input port="source"> <p:pipe step="expand" port="result"/> 4 </p:input> <p:input port="stylesheet"> 6 <p:document href="docbook.xsl"/> </p:input> 8 <p:option name="initial-mode" select="$imode"/> <p:parameter name="home" 10 value="http://example.com/"/> </p:xslt>
1 <p:xslt name="db2html" version="2.0"> 2 <p:input port="source"> <p:pipe step="expand" port="result"/> 4 </p:input> <p:input port="stylesheet"> 6 <p:document href="docbook.xsl"/> </p:input> 8 <p:option name="initial-mode" select="$imode"/> <p:parameter name="home" 10 value="http://example.com/"/> </p:xslt>
1 <p:xslt name="db2html" version="2.0"> 2 <p:input port="source"> <p:pipe step="expand" port="result"/> 4 </p:input> <p:input port="stylesheet"> 6 <p:document href="docbook.xsl"/> </p:input> 8 <p:option name="initial-mode" select="$imode"/> <p:parameter name="home" 10 value="http://example.com/"/> </p:xslt>
1 <p:xslt name="db2html" version="2.0"> 2 <p:input port="source"> <p:pipe step="expand" port="result"/> 4 </p:input> <p:input port="stylesheet"> 6 <p:document href="docbook.xsl"/> </p:input> 8 <p:option name="initial-mode" select="$imode"/> <p:parameter name="home" 10 value="http://example.com/"/> </p:xslt>
A p:input identifies input to a port; its subelements identify a document or sequence of documents:
<p:document href="uri"/> reads input from a URI.
<p:inline>...</p:inline> provides the input as literal content in the pipeline document.
<p:pipe step="stepName" port="portName"/> reads from a readable port on some other step.
<p:empty/> is an empty sequence of documents.
Unbound inputs automatically bind to the default readable port.
1 <p:xslt name="db2html" version="2.0"> 2 <p:input port="source"> <p:pipe step="expand" port="result"/> 4 </p:input> <p:input port="stylesheet"> 6 <p:document href="docbook.xsl"/> </p:input> 8 <p:option name="initial-mode" select="$imode"/> <p:parameter name="home" 10 value="http://example.com/"/> </p:xslt>
Semantically, the version attribute is indistinguishable from:
<p:option name="version" value="2.0"/>
Steps only accept the options that they declare.
Steps can compute option values using XPath.
Options are strings.
1 <p:xslt name="db2html" version="2.0"> 2 <p:input port="source"> <p:pipe step="expand" port="result"/> 4 </p:input> <p:input port="stylesheet"> 6 <p:document href="docbook.xsl"/> </p:input> 8 <p:option name="initial-mode" select="$imode"/> <p:parameter name="home" 10 value="http://example.com/"/> </p:xslt>
Steps only accept parameters if they are declare a parameter input port.
Any number of parameters can be passed to steps.
Parameter names are not known in advance.
Pipelines can manipulate sets of parameters for different steps.
There's a special defaulting rule for the common case that parameters passed to the p:pipeline should automatically be passed to the steps that the pipeline contains.
Compound steps contain other steps (subpipelines)
Compound steps don't have separate declarations; the number of inputs, outputs, options, and parameters that they accept can vary on each instance.
There's no mechanism in XProc V1.0 for user-defined compound steps.
1 <p:group name="xincxform"> 2 <p:output port="result"> <p:pipe step="db2html" port="result"/> 4 </p:output> 6 <p:xinclude/> <p:xslt name="db2html"> 8 <p:input port="stylesheet"> <p:document href="docbook.xsl"/> 10 </p:input> </p:xslt> 12 </p:group>
1 <p:group name="xincxform"> 2 <p:output port="result"> <p:pipe step="db2html" port="result"/> 4 </p:output> 6 <p:xinclude/> <p:xslt name="db2html"> 8 <p:input port="stylesheet"> <p:document href="docbook.xsl"/> 10 </p:input> </p:xslt> 12 </p:group>
A p:output binds the output port of a compound step only. Outputs of atomic steps are never bound.
<p:document href="uri"/>, <p:inline>...</p:inline>, and <p:empty/> provide the specified content as the output on the port.
<p:pipe step="stepName" port="portName"/> provides the specified output as output on the port. It must be bound to a step in the subpipeline.
Unbound outputs automatically bind to the primary output port of the last step (in document order) in the contained pipeline.
1 <p:group> 2 <p:output port="result"/> 4 <p:xinclude/> 6 <p:xslt> <p:input port="stylesheet"> 8 <p:document href="docbook.xsl"/> </p:input> 10 </p:xslt> </p:group>
A p:pipeline is a compound step. It has several special properties:
It's the thing that the pipeline processor actually runs. Processing always begins with a pipeline.
A pipeline can import other pipelines or pipeline libraries.
A pipeline can call an imported pipeline (or itself) as an atomic step.
1 <p:pipeline name="main"> 2 <p:input port="document" primary="true"/> <p:input port="stylesheet"/> 4 <p:output port="result"/> 6 <p:xinclude/> 8 <p:xslt version="2.0"> <p:input port="stylesheet"> 10 <p:pipe step="main" port="stylesheet"/> </p:input> 12 </p:xslt> </p:pipeline>
Conditional processing: p:choose
Iteration: p:for-each
Selective processing: p:viewport
Exception handling: p:try/p:catch
Building libraries: p:pipeline-library
Choose one of a set of subpipelines based on runtime evaluation of an XPath expression
The XPath context can be any document, even documents generated by preceding steps.
Constraint: all of the subpipelines must have the same number of inputs and outputs, with the same names. This makes the actual subpipeline selected at runtime irrelevant for static analysis.
1 <p:choose> 2 <p:when test="/root[@version=2]"> <p:output port="result"/> 4 ... </p:when> 6 <p:when test="/root"> <p:output port="result"/> 8 ... </p:when> 10 <p:otherwise> <p:output port="result"/> 12 ... </p:otherwise> 14 </p:choose>
(Or, the reason our last call didn't stick...)
Pipeline authors can specify either XPath 1.0 or XPath 2.0
Implementors can implement either XPath 1.0 or XPath 2.0
If XPath 1.0 is requested and the processor uses XPath 2.0, it must use XPath 1.0 compatibility mode
If XPath 2.0 is requested and the processor uses XPath 1.0, it must only evaluate expressions that it knows would give the same result.
Apply the same subpipeline to a sequence of documents
A sequence can be constructed in several ways:
As the result of a previous step
By selecting nodes from a document or set of documents
Literally in the p:input binding
XProc doesn't support counted iteration (do this three times) or iteration to a fixed point (do this until some condition is true)
1 <p:for-each> 2 <p:iteration-source select="//chapter"/> <p:output port="result"/> 4 <p:xslt> 6 <p:input port="stylesheet"> <p:document href="docbook.xsl"/> 8 </p:input> </p:step> 10 </p:for-each>
Apply a subpipeline to some subtree in a document
In other words, process just a “data island” in a document, without changing the surrounding context
1 <p:viewport match="h:div[@class='chapter']"> 2 <p:output port="result"/> 4 <p:insert position="first-child"> <p:input port="insertion"> 6 <p:inline> <hr xmlns="http://www.w3.org/1999/xhtml"/> 8 </p:inline> </p:input> 10 </p:insert> </p:viewport>
Try to run the specified subpipeline
If something goes wrong, catch the error and try the recovery subpipeline
All the output from the initial pipeline must be discarded
If something goes wrong in the catch, the try fails
Constraint: both the subpipelines must have the same number of inputs and outputs, with the same names. This makes the actual subpipeline that produces the output irrelevant for static analysis.
1 <p:try name="tryit"> 2 <p:group> <p:output port="out"/> 4 ... </p:group> 6 <p:catch> <p:output port="out"/> 8 ... <p:input ...> 10 <p:pipe step="tryit" port="errors"/> </p:input> 12 ... </p:catch> 14 </p:try>
Useful pipelines can be stored in a library.
Libraries can be imported to provide that functionality in a new pipeline.
1 <p:pipeline-library namespace="..."> 2 <p:import href="os-library.xml"/> 4 <p:pipeline name="xinclude-and-style">... 6 <p:pipeline name="xinclude-and-db2html">... 8 <p:pipeline name="get-tide-information">... 10 </p:pipeline-library>
30 required steps
10 optional steps
(Or, the other reason our last call didn't stick...)
We used to have two steps, a required XSLT 1.0 step and an optional XSLT 2.0 step
Now we have a single XSLT step with a version attribute
Authors can request the version they want, implementors can provide the version they want, with rules for what to do when they don't line up.
Because automic steps have a fixed signature, there are bits of the XSLT signature that don't make a lot of sense in the XSLT 1.0 case, but it's mostly ok.
QNames in XPath expressions are just strings.
The binding of prefixes to namespace names depends on context.
Options, containing XPath expressions that contain QNames, can be passed from one context to another.
Doctor, doctor! It hurts when I do that!
(Deep breath everyone, this is not pretty.)
Imagine that I have a configuration file that contains XPath expressions:
1 <my:config xmlns:my="http://www.example.com/ns/my" 2 xmlns:c="http://www.example.com/ns/contacts"> <my:filter test="c:person/c:name='Jones'" /> 4 </my:config>
(Credit to Jeni Tennison for this example.)
Now imagine that I want to use elements from that context in an option to a step:
1 <p:matching-documents> 2 <p:option name="test" select="concat('/h:html/h:head/rdf:RDF[', 4 /my:config/my:filter/@test, ']')"> <p:pipe step="top" source="config" /> 6 </p:option> </p:matching-documents>
That's equivalent to passing the following string as the test option:
"/h:html/h:head/rdf:RDF[c:person/c:name='Jones']"
But what if the namespace binding for “c:” isn't in this pipeline; or worse, what if it has a different binding? (Remember, the string came from a different context.)
And for the worst case of all, suppose this step is in a pipeline that you imported from a library and can't change?
We can fix this with the p:namespaces element. Here's that step again:
1 <p:matching-documents> 2 <p:option name="test" select="concat('/h:html/h:head/rdf:RDF[', 4 /my:config/my:filter/@test, ']')"> <p:pipe step="top" source="config" /> 6 <p:namespaces element="/my:config/my:filter"/> </p:option> 8 </p:matching-documents>
Now the bindings for all of the prefixes used in @test will be explicitly provided.
XProc implementations are starting to surface:
My own, XML Pipeline Processor, https://xproc.dev.java.net
xprocxq, http://code.google.com/p/xprocxq/
XSP.NET, http://xsp-net.sourceforge.net/
Cocoatron, http://cocoatron.com/
Plus several others not yet publicly announced, to the best of my knowledge.
We're making progress
Second, and hopefully final, last call after the holidays
Recommendation this spring?
Your feedback is solicited!