Credit where credit is due
 Terry Allen, Jon Bosak, Paul
Grosso, Eve Maler, Murray Maloney
Terry Allen, Jon Bosak, Paul
Grosso, Eve Maler, Murray Maloney
Norm is an XML Standards Architect at Sun Microsystems, Inc.
Has more than a decade of experience with SGML and XML publishing systems.
Elected member of the W3C Technical Architecture Group; also chair of the XML Processing Model Working Group, co-chair of the XML Core Working Group, and member of, and editor for, the XSL Working Group at the W3C.
Chair of the DocBook Technical Committee at OASIS. Also editor for the Entity Resolver Technical Committee and a member of the RELAX NG Technical Committee.
Specification lead for JSR 206, the Java API for XML Processing in the Java Community Process. Occasional
Original developer and project lead for the DocBook DSSSL and DocBook XSL Stylesheet projects. Creator and contributor to numerous open-source projects.
Understanding the information that you have
Adding structure to your information
Off the shelf or roll your own?
What kind of markup and how much?
Planning for the future
Business needs evolve
Change happens
Terry Allen, Jon Bosak, Paul
Grosso, Eve Maler, Murray Maloney
Creation and modification
Storage and archiving
Use
Authoring
Editing
Validation
Review
Conversion
Transformation
Classification
Assembly
Reuse
Exchange
Printing
Navigational structures
Indexes
Tables of Contents
Reading online
Navigational structures
Searching
Extraction
Analysis
Enforce requirements about the structure and meaning of information assets
Improve management of whole and partial documents
Support applications that format, index, and otherwise process documents
Provide metadata about the content of documents
Procedural
Linear flow with embedded formatting commands
troff, RTF, WordStar “dot commands”; TeX tends in this direction, though LaTeX demonstrates that you can do declarative markup with TeX too
Office documents without using “styles”
Declarative markup
Hierarchical structure with semantic identifiers
SGML, XML
Office documents with rigorous use of carefully designed styles
Explicit rules about what goes where
Structural integrity
Searching
Cross-referencing
It's as much art as it is science
It's a collaboration between domain experts, technologists, managers, and other groups that have responsibility for information assets
It's very dependent on the nature of the information involved and the ways that it is now (and may in the future) be used
Sometimes it makes sense to roll your own
Sometimes it makes sense to adopt a standard
Fits your needs explicitly
At least, to the extent that your analysis and design identified and codified those needs
It's hard work
Remember the whole toolchain
Provides the benefit of an existing community of users
Has significant tool advantages
Possibly not quite the right markup
When does one-size-fits-all fit you?
| 1½ oz | Tequila | |
| ½ oz | Paula's Texas Orange | |
| 1 oz | Lime juice |
Rub the rim of a margarita glass with the rind of a lime and dip rim in salt. Shake ingredients with ice and strain into glass.
<beverage virgin="false">
<name>Margarita</name>
<source>Paula Angerstein</source>
<ingredientList>
<ingredient>
<quantity units="oz">1.5</quantity>
<name>Tequila</name>
</ingredient>
<ingredient>
<quantity units="oz">0.5</quantity>
<name>Paula’s Texas Orange</name>
</ingredient>
<ingredient>
<quantity units="oz">1</quantity>
<name>Lime Juice</name>
</ingredient>
</ingredientList>
<preparation>
<p>Rub the rim of a margarita glass with the rind of a lime and
dip rim in salt. Shake ingredients with ice and strain into
glass.</p>
</preparation>
</beverage>
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Margarita</title> <meta name="source" content="Paula Angerstein"/> <meta name="virgin" content="false"/> </head> <body> <h1>Margarita</h1> <dl> <dt><span class="q">1½</span> <span class="u">oz</span> Tequila</dt> <dt><span class="q">½</span> <span class="u">oz</span> Paula's Texas Orange</dt> <dt><span class="q">1</span> <span class="u">oz</span> Lime juice</dt> </dl> <p>Rub the rim of a margarita glass with the rind of a lime and dip rim in salt. Shake ingredients with ice and strain into glass.</p> </body> </html>
Select a standard that looks close and customize it
Some interchange and tool advantages
Markup that more closely fits your needs
Customization can be hard too
<article xmlns="http://docbook.org/ns/docbook" version="5.0-extension recipes"> <info> <title>Margarita</title> <releaseinfo role="virgin">false</releaseinfo> <author><personname>Paula Angerstein</personname> </author> </info> <ingredientlist> <ingredient units="oz" quantity="1.5">Tequila</ingredient> <ingredient units="oz" quantity="0.5">Paula's Texas Orange</ingredient> <ingredient units="oz" quantity="1">Lime juice</ingredient> </ingredientlist> <section xml:id="preparation"> <title>Preparation</title> <para>Rub the rim of a margarita glass with the rind of a lime and dip rim in salt. Shake ingredients with ice and strain into glass.</para> </section> </article>
Costs/benefits
More markup = more cost
More markup = more benefit?
Markup results
Insufficient markup
Too much markup
Incorrect markup
Remember your authors
<glossentry>crlf: /ker´l@f/, /kru´l@f/, /C·R·L·F/, n.
(often capitalized as ‘CRLF’) A carriage return (CR, ASCII
0001101) followed by a line feed (LF, ASCII 0001010). More loosely,
whatever it takes to get you from the end of one line of text to the
beginning of the next line. See newline. Under Unix influence this
usage has become less common (Unix uses a bare line feed as its
‘CRLF’).</glossentry>
From The Jargon File, version 4.4.7 by Eric S. Raymond
<glossentry xml:id="crlf"> <glossterm>crlf</glossterm> <!-- pronunciation? --> <glossdef> <para>(often capitalized as ‘CRLF’) A carriage return (CR, <acronym>ASCII</acronym> 0001101) followed by a line feed (LF, <acronym>ASCII</acronym> 0001010). More loosely, whatever it takes to get you from the end of one line of text to the beginning of the next line. <xref linkend="newline"/>. Under <productname>Unix</productname> influence this usage has become less common (<productname>Unix</productname> uses a bare line feed as its ‘CRLF’).</para> </glossdef> </glossentry>
<glossentry xml:id="crlf"> <glossterm>crlf</glossterm> <glossdef> <para><parenthetical-remark>(often capitalized as ‘<acronym>CRLF</acronym>’)</parenthetical-remark> A <charname>carriage return</charname> <parenthetical-remark>(<acronym>CR</acronym>, <acronym>ASCII</acronym> <binary>0001101</binary>)</parenthetical-remark> followed by a <charname>line feed</charname> <parenthetical-remark>(<acronym>LF</acronym>, <acronym>ASCII</acronym> 0001010)</parenthetical-remark>. More loosely, whatever it takes to get you from the end of one line of text to the beginning of the next line. <xref linkend="newline"/>. Under <productname>Unix</productname> influence this usage has become less common <parenthetical-remark>(<productname>Unix</productname> uses a bare <charname>line feed</charname> as its ‘<acronym>CRLF</acronym>’).</para> </glossdef> </glossentry>
<glossentry xml:id="crlf"> <glossterm>crlf</glossterm> <glossdef> <para>(often capitalized as ‘CRLF’) A carriage return (CR, <acronym>ASCII</acronym> 0001101) followed by a line feed (LF, <abbrev>ASCII</abbrev> <acronym>0001010</acronym>). More loosely, whatever it takes to get you from the end of one line of text to the beginning of the next line. <link linkend="foo">newline</link>. Under <trademark>Unix</trademark> influence this usage has become less common (<trademark>Unix</trademark>> uses a bare <foreignphrase>line feed</foreignphrase> as its ‘CRLF’).</para> </glossdef> </glossentry>
How big is the content your identifying?
Word sized?
Phrase sized?
Paragraph sized?
Container sized?
Enforce useful structural rules
A visual model for XML structures
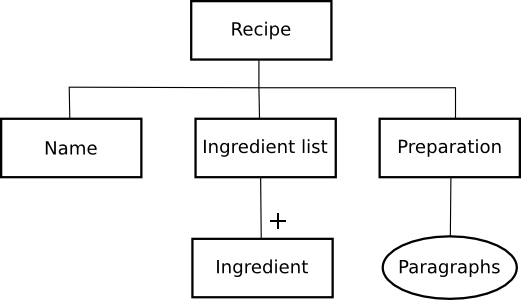
Different validation technologies impose different design constraints
Common constraint languages
DTD
W3C XML Schema
RELAX NG Grammar
Schematron
Widely understood (at least by us old timers)
Supported by every validating XML parser (by definition)
Support entities
No ambiguity allowed*
No co-constraints*
Not in XML document syntax
Almost no data types
* We'll come back to ambiguity and co-constraints in a moment.
Supports typed object graphs
Supports scoped identity constraints
No ambiguity allowed
No co-constraints
Widely considered hard to understand
Easy to customize
Allows ambiguity
Supports co-constraints
Supports simple data types
Not (yet) as widely supported in tools
Allows very sophisticated validation with co-constraints, etc.
Not grammar based
Ideal in combination with one of the other languages
If you know where you are in a grammar, can you tell what must come next?
Consider the case where you want to allow an optional documentation element to come either before or after an optional product element. One compact notation for this content model would be: documentation*, product?, documentation*
This is ambiguous
If you see a documentation element, you can't tell if a product element will be next or not.
Sometimes it's possible to restate ambiguous content models unambiguously: (a,b)|(a,c) is the same as a,(b|c).
Sometimes doing so really complicates the content model
Sometimes it can't be done without relaxing or otherwise changing the constraints
This attribute or this content model.
If this attribute, then also this attribute.
If this attribute value, then this content model.
If this attribute value, then also this attribute.
Why are you doing this?
What are your goals?
What documents are you interested in?
Better validation?
Greater productivity?
Multiple presentation formats?
Improved searching?
Personalization?
Technical documentation
Reference materials
Correspondence
Purchase orders/business documents
Identify potential needs; define them thoroughly
Classify them into categories
Validate your needs against similar data
Don't worry about the angle brackets now
Identify the basic structures you need to encode
Legacy documents
Books/articles/whitepapers
Text/tables/lists/graphics/video/equations/etc.
Multiple languages
Character sets
Classify the structures into logical groups
Validate the analysis
Structural components
Content components
Presentational components
Metadata components
Books
Chapters
Tables/figures/examples
Lists/list items
Paragraphs
Part numbers, measurements
Quantities, prices
Postal addresses, phone numbers
Commands and functions
Descriptions
Special formatting (emphasis or verbatim)
Required or forbidden line/paragraph/page breaks
Indented regions
Boxes, borders, and shading
Necessary metadata
Cross references and other links
Co-occurrence constraints
Use semantic indicators (discard formatting)
Avoid duplication of data (headers/footers, ToCs, release dates)
Identify content already maintained somewhere else
Identify labeled containers
Look for wrappers
Look for block vs. inline containers
Keep processing expectations in mind
Select the structures that the schema should address
Build the models
Populate the locations where authors have choices (what's allowed where?)
Word sized
Phrase sized
Paragraph sized
Container sized
Be generous, don't exclude similar elements without good cause
Make connections within the model
Document assembly instructions
Implicit cross references
Explicit cross references
Make connections to the outside world
Validate the model
Overall document hierarchy
Mid-level elements
Low-level elements
(Probably a little of both.)
Balance costs and benefits
Be realistic
Enforce restrictions
Don't encourage “tag abuse” (we'll come back to that)
Understand the benefits
Make sure your authors do too
One of the hardest aspects of markup design is choosing markup that's “rich enough” without encouraging authors to resort to tag abuse:
Choosing markup for its formatting effect
Inconsistent markup because only formatting is considered important
Using the wrong markup (paragraph that begins "Note:" instead of note)
Using elements without really understanding what they mean (copyright vs. trademark)
Write your schema (harness the power of XML elements, attributes, etc.)
Angle brackets at last!
Consider using a set of related schemas
Modularity
Extensibility
Planning for change
Elements
Attributes
Processing instructions
Comments
Text
Identifiers
Element content
Simple content (maybe typed values, depending on schema language)
Mixed content
Delimited list of values
Simple types (selection depends on schema language)
Common attributes
xml:id
xml:base
Allowed anywhere
Not checked by grammar-based validation
Very flat internal structure:
<?pitarget some content goes here?>
Often presented like pseudo-elements:
<?pitarget this="that" that="the other"?>
But that's just a convention; there's usually no validation.
Use sparingly
Usually ignored
Often used to “comment out” blocks of text
They don't nest!
Avoid structured comments
Use processing instructions instead
Globally unique
Locally unique
What does global mean?
In markup, it often means “document wide”. (But consider your assembly technologies.)
XML provides an attribute type, “ID”, for this purpose. W3C XML Schema and RELAX NG use that type too.
The XML attribute type “IDREF” is for pointing to things with IDs.
Spell the name of your ID attributes this way: “xml:id”.
It's easiest to point to things that have IDs. Think carefully about how you want to manage them.
The easy answer: allow them optionally everywhere.
Unique within a particular context: for example, all recipe titles must be unique within a single cookbook
Some schema languages support this better than others
Interchange
Reference
Authoring
Conversion
Presentation
Entities
XInclude
Macro processing
Can be used for both simple content and structural content
External parsed entities can have multiple root elements (but that makes them hard to validate independently)
They're supported by all XML parsers
ID/IDREF checking works as expected
They're an artifact of DTDs and use DTD syntax:
<!DOCTYPE book [ <!ENTITY chap01 SYSTEM "chapter-01.xml"> ]> <book xmlns="..."> ... &chap01; ... </book>
Transcludes one document into another
Transcluded document must be a well-formed document
No ID/IDREF checking across document boundaries
Requires namespace support; is widely supported.
You can “roll your own” here, too
Tools like XSLT, especially XSLT 2.0, provide all the power necessary to define your own macro processing.
Such solutions are usually much like XInclude: they require well-formed documents for transclusion and provide no automatic ID/IDREF checking across document boundaries.
(Use a standard vs. roll your own again)
Suspiciously similar elements (div1, div2, div3 vs divtitle1, divtitle2, divtitle3)
Schizophrenic elements (a single list element that can contain either items or messages)
Recursive elements
Elements that reinvent other markup (entities, XInclude)
Baroque content models
Ambiguous content models
Elements that can mistakenly be empty
Limited occurrences
Problematic mixed content
One element in different contexts
One element with attribute values
Containers versus flat structures
Documents as data
Generated text
Reuse (reader context)
How many legacy formats?
Legacy paper?
Consistency of original information
Automated conversion or rekeying?
Best case scenario
Worst case scenario
The legacy documents have a lot of implicit or explicit structure
The legacy format exposes those structures
Those structures are used with complete regularity
In this case, programmatic conversion will be very valuable.
The legacy documents have no useful implicit or explicit structure
The explicit structures that they do have (e.g., “styles”) are used in wildly inconsistent ways
There's no way to extract any useful structure from the legacy format
In this case, programmatic conversion won't help much.
Output to paper
Output to the web
Specialty requirements
Government/industry standards
No, you don't, really.
Atom, DocBook, HTML, NLM, TEI, etc.
Subsets
Supersets
Well, if you must...
Skip the markup design phase
Don't consider the markup design as important as the other tools
Don't plan for the future
Develop it in isolation from the rest of the production system
Don't understand your goals
Don't keep good records
Accept change
Accept that no model is perfect
Analyze first, model later
No angle brackets until the analysis is done
Everyone has to understand the analysis and design
Record everything
Write down the rationale for all decisions
Choose names carefully
Be systematic
Set limits (avoid too much markup)
Establish useful markup (vs. absolutely correct markup)
A DocBook msgset describes a set of possibly related messages.
<msgset>
<title>Some messages</title>
<msgentry>
<msg>
<msgmain>
<msgtext>Some message</msgtext>
</msgmain>
<msgrel>
<msgtext>Some related message</msgtext>
</msgrel>
<msgsub>
<msgtext>Some sub-message</msgtext>
</msgsub>
</msg>
<msginfo>
<msgaud>Network administrators</msgaud>
<msglevel>Error</msglevel>
<msgorig>NIC hardware</msgorig>
</msginfo>
<msgexplan>
<para>…</para>
</msgexplan>
</msgentry>
<!-- ... -->
</msgset>
In practice, that much detail is overwhelming to authors.
<msgset>
<title>Some messages</title>
<simplemsgentry msgaud="netadmin" msglevel="error"
msgorig="NIChardware">
<msgtext>Some message</msgtext>
<msgexplan>
<para>…</para>
</msgexplan>
</simplemsgentry>
<!-- ... -->
</msgset>
Record everything
Write down the rationale for all decisions
Abstract away from presentation
Go beyond the legacy
What else would be useful in the future?
Leverage domain experts as much as possible
Iterate over the design
Define a reporting procedure
Encourage feedback
Define a stable and sane update policy
Take maintenance seriously
Be responsive
Me: <Norman.Walsh@Sun.COM>
This presentation: http://nwalsh.com/docs/presentations/2007/csw/