Abstract
This paper explores some of the design choices made in casting DocBook from an XML DTD to a RELAX NG Grammar. It highlights specific areas where RELAX NG provides features and benefits to schemas designed for direct authorship by human beings, particularly schemas with many mixed content elements.
One potential direction for the evolution of DocBook is presented.
Table of Contents
DocBook is an XML vocabulary for writing documentation. It is particularly well-suited to books and papers about computer hardware and software, though it is by no means limited to them. DocBook is currently defined by an XML (or SGML) DTD. Because it is large and robust, and because its main structures correspond to the general notion of what constitutes a book, DocBook has been adopted by a large and growing community of authors. DocBook is supported “out of the box” by a number tools, both commercial and free.
A typical DocBook document is shown in Figure 1, “A Typical DocBook Document”. It consists of a book which contains some metadata and a chapter. The chapter contains a couple of block elements and those, in turn, contain some inlines.
Figure 1. A Typical DocBook Document
<book>
<bookinfo>
<title>A Book Title</title>
<author>
<firstname>John</firstname>
<surname>Doe</surname>
</author>
</bookinfo>
<chapter>
<title>The First Chapter</title>
<para>Some <emphasis>text</emphasis>.</para>
<programlisting>public class HelloWorld {
public static void main(String args[]) {
System.out.println("Hello, World!");
}
}</programlisting>
</chapter>
</book>
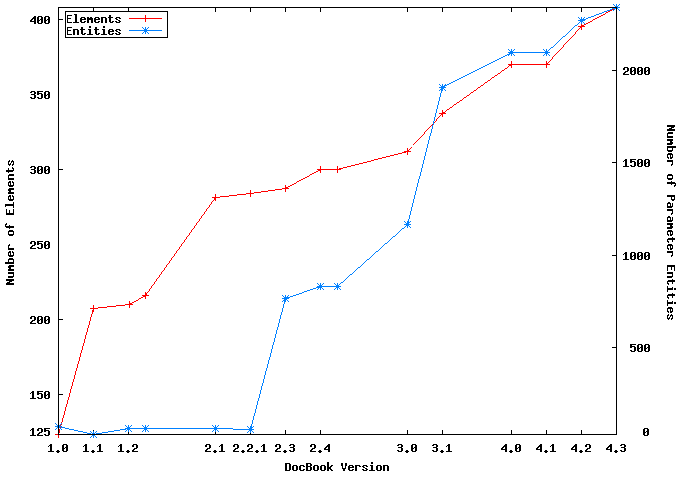
DocBook is a success. It’s been around for more than a decade and is still actively used and maintained. As an XML application, Version 4.3 boasts 408 elements and more than 2300 parameter entities. As DTDs go, that’s pretty extreme. DocBook has served as an effective, sometimes too effective, stress test for more than one XML application, and in the days before XML, it stressed a few SGML applications beyond their limits as well.
Figure Figure 2, “DocBook Growth” plots DocBook growth (in terms of the number of elements and parameter entities) over its release history.
But DocBook has not been an unqualified success:
-
Growth by accretion has resulted in some content models that are at best odd and at worst broken in pretty obvious ways.
-
Ten years of incremental growth has also changed the scale of DocBook. Designing a schema of roughly 400 elements is different than designing a schema of roughly 100. Logically extending decisions that looked regular and consistent when DocBook had 100 elements has not always resulted in a design that continues to look regular and consistent.
-
The DTD fails to capture some significant constraints, for example, that elements like article must have a title.
-
DocBook predates the web. It aches for a more web-friendly approach to linking.
-
Originally designed as an exchange DTD, it has largely become an authoring DTD. Exchange and authoring aren’t opposing design centers, but they are different. It’s worth reconsidering DocBook in terms of authoring.
-
While DocBook is a shining example of parameter entity customization, parameter entity customization is fiendishly hard.
This paper discusses the redesign of DocBook as a native RELAX NG grammar. The goals of this redesign are to produce a schema that:
-
“feels like” DocBook. Most existing documents should still be valid or it should be possible to transform them in simple, mechanical ways into valid documents.
-
enforces as many constraints as possible in the schema. Where augmenting the RELAX NG grammar with Schematron rules is a good strategy, do so.
-
cleans up the content models.
-
gives users the flexibility to extend or subset the schema in an easy and straightforward way.
-
can be used to generate XML DTD and W3C XML Schema versions of DocBook.
Several high-level observations can be made about the “shape” DocBook:
-
It’s mostly hand authored. Unlike SOAP envelopes, purchase orders, and XML/RPC invocations where the XML is most likely generated by a program, humans write DocBook.
-
It’s mostly read by humans. DocBook documents, by and large, aren’t consumed by unmarshalling processes building Java object graphs or other programmatic interpretation. DocBook documents attempt to model the full richness of human literary expression: they have footnotes and figures and tables and cross-references and funny glyphs and mathematics and poetry and a great many other things.
-
As a consequence of the fact that they’re mostly read by humans, DocBook documents are usually rendered into a presentation form, be that a web page or a printed page. DocBook attempts to separate content from presentation; there are relatively few elements that exist only to carry presentation information (like fonts and colors), but most processing expectations are described in terms of presentation.
-
DocBook contains a lot of mixed content. Of the 400 or so elements, almost half contain mixed content. Very few have “simple content,” dates, numbers, or other simple values with no possibility of additional markup.
RELAX NG is not simply well suited to describing vocabularies for which similar observations can be made, it is clearly superior to the other popular grammar-based schema languages: DTDs and W3C XML Schema. It’s not clear (one way or the other) whether the same advantages apply to vocabularies that are very different in “shape.”
The balance of this paper is a survey of the elements, or classes of elements, that occur in DocBook with a discussion of the specific choices made in recasting DocBook into a RELAX NG grammar. Each choice highlights a particular RELAX NG feature that is employed to simplify the schema.
DocBook NG attempts to address several other long-standing issues, such as universal linking, not directly related to validation. Those issues are not discussed in this paper.
This paper describes DocBook NG “Bourbon”, the second experimental DocBook NG release. The first release was “Absinthe”. Since this paper was written, another release has been made, “Cachaça”. The practical difference in “Cachaça” is that a number of patterns have been renamed to reduce the possibility of pattern name collisions when DocBook is combined with other vocabularies, such as the TEI. In principle, it is the same design.
the section called “Appendix A: General Notes about RELAX NG” offers a brief summary of RELAX NG, highlighting some of the features relevant to this paper.
Below the level of chapters and sections, lies the actual meat of a document: its textual content. This is where “block level” elements: paragraphs, lists, tables, figures, equations, etc. reside. Inside the “block level” elements, there are “inline” elements: phrases, links, technical terms, footnotes, etc.
In DocBook V4.x, these blocks and inlines are constructed from a byzantine collection of parameter entities designed to provide flexibility for customizers while simultaneously satisfying the XML constraint of determinism in content models.
Relaxation of the determinism constraint in RELAX NG frees us to construct our schema directly using the familiar abstraction of block and inline elements.
In particular, the result is straightforward looking patterns such as these:
Example 1. Blocks
blocks = nopara.blocks | para.blocks | extension.blocks nopara.blocks = formal.blocks | informal.blocks | list.blocks | admonition.blocks … para.blocks = db.anchor | db.para | db.formalpara | db.simpara formal.blocks = db.equation | db.example | db.figure | db.table graphic.blocks = db.mediaobject | db.screenshot technical.blocks = db.procedure extension.blocks = notAllowed
A customization can simply redefine one of these patterns to extend or subset the relevant class of block element. For example, adding a new kind of admonition to “admonition.blocks” allows it to appear anywhere the other admonitions are allowed. The special pattern “notAllowed” is used for “extension.blocks” which is an extension point for customizers.
The pattern “notAllowed” never matches any node in a document. Allowing it as an alternative in blocks has no effect in the standard DocBook NG schema because it will never match. But a customization layer can redefine “extension.blocks” to add new elements.
This isn’t strictly necessary. Unlike parameter entities in DTDs which are defined exactly once, a RELAX NG grammar can add choices to an existing pattern. But adding new block (and new inline) elements is a very likely extension; providing a named pattern for this purpose will help customizers in determining how to make the extension and will serve to make the customization layer’s intent clearer.
Inlines are defined in a similar way. Close examination of the structure of inline definitions reveals one way that DocBook NG takes advantage of non-determinism:
Example 2. Inlines
ubiq.inlines = db.inlinemediaobject | db.anchor | db.remark inlines = text | ubiq.inlines | general.inlines | domain.inlines | extension.inlines general.inlines = publishing.inlines | product.inlines | bibliography.inlines … link.inlines = db.xref | db.uri | db.anchor extension.inlines = notAllowed
As you can see, anchor occurs in the ubiquitous inlines (ubiq.inlines) and in the linking inlines (link.inlines) because it is simultaniously ubiquitous and a linking inline. This means that in the expansion of “inlines”, it appears twice:
effective-inlines = text | … | db.anchor | … | db.anchor | …
In a DTD or W3C XML Schema content model, that’s an error. In RELAX NG, it isn’t.
Freedom to define groups of block and inline elements without the constraints imposed by DTDs has allowed the DocBook NG schema to greatly simplify many of the content models.
DocBook V4.x has setinfo, bookinfo, chapterinfo, appendixinfo, sectioninfo, etc. There’s an historical reason for this: customizers might very well want to adjust the content models of info elements at different levels. For example, a copyright statement might be required at the book level, or an an author forbidden at the sub-section level.
In DTDs, there’s only one content model allowed per element name. So in order to support independent customization, each info element must have a different name.
This is tedious and confusing for authors, especially since DocBook abandons this model at the very bottom level, using blockinfo for a variety of block-level elements.
In RELAX NG this problem is easy to solve: the schema can define many patterns that match an element named info. The book element begins with a “book.info” pattern, the chapter element begins with a “chapter.info” pattern, etc. Each of these patterns matches an element called “info”. Customizers are thereby free to redefine the info element depending on its context without forcing authors to use different names in each place.
This is an insoluble problem in DTDs. In W3C XML Schema, it would be possible to achieve much the same result by making each of the info elements local to the element that contains it. To customize an info element in that case would require replacing the declaration for the containing element. This is a less flexible design, but it’s not clear that it would be a serious practical limitation.
RELAX NG also allows us to enforce the constraint that an optional info element, if it occurs, must occur first, even in mixed content. This opens the door for allowing info optionally even in contexts like para where it has never been allowed before.
In DTDs and W3C XML Schema, mixed content always has this pattern:
(info|abbrev|emphasis|…|#PCDATA)*
which doesn’t constrain the info element to occur first or even to occur only once.
In RELAX NG, the following pattern can enforce such a constraint:
(info?, (abbrev|emphasis|…|text)*)
It makes the optional info element occur first and not more than once.
Also related to info elements, RELAX NG can solve another long standing problem: titles that are effectively optional in the DTD version of DocBook where they should be required.
Consider the case of article. In order to allow the title to be used directly in the article or in the articleinfo, it has to be made optional in both places. This allows not only valid articles, like those shown in Example Example 3, “Valid Articles”, but also invalid articles, like those shown in Example Example 4, “Invalid Articles”. Articles are required to have exactly one title, but that constraint can’t be enforced in DTDs.
Example 3. Valid Articles
<article> <title>Some Article Title</title> <para>Some content.</para> </article> <article> <articleinfo> <title>Some Article Title</title> <author><firstname>Jane</firstname><surname>Doe</surname></author> </articleinfo> <para>Some content.</para> </article>
Example 4. Invalid Articles
<article> <para>Some content without a title.</para> </article> <article> <title>Is This the Title?</title> <articleinfo> <title>Or Is This?</title> </articleinfo> <para>Some content.</para> </article>
RELAX NG gives us the tools needed to tackle this problem. First, define two patterns for the info element: one which requires a title and one which forbids it. Then define an article along the lines shown in Example 5, “Better Title Constraints”.
Example 5. Better Title Constraints
element article {
(title, info.titleforbidden) | info.titlerequired,
…
}
Note that the actual element name is “info” in either case, but the pattern “info.titleforbidden” defines an info element that may not contain a title and the pattern “info.titlerequired” defines an info element that must contain a title.
Several elements have attribute co-constraints. That is, there are combinations of attributes that are required and combinations that are not allowed. The ability to specify that the individual attributes are either optional or required is not sufficient to establish these constraints.
This is a technique already seen in the last example of the section called “Appendix A: General Notes about RELAX NG”.
Consider the class attribute on biblioid, it can have any one of the following values: doi, isbn, issn, libraryofcongress, pubnumber, uri, or other. If it has the value “other,” then the otherclass attribute must be specified. If the class is not “other,” then the otherclass attribute is not allowed.
RELAX NG makes it possible to express this constraint:
Example 6. Class Attribute on biblioid
biblio.class-enum.attribute =
attribute class {
"doi"
| "isbn"
| "issn"
| "libraryofcongress"
| "pubnumber"
| "uri" }?
biblio.class-other.attributes =
attribute class { "other" }?,
attribute otherclass { xsd:NMTOKEN }
biblio.class.attrib = (biblio.class-enum.attribute | biblio.class-other.attributes)
The pattern “biblio.class.attrib” matches exactly the constraint that must be enforced: if the class attribute is “other”, otherclass is required, otherwise it is forbidden.
Along the same lines as titles and co-constraints, RELAX NG allows us to untangle the HTML and CALS Table Models. In DocBook V4.3, HTML Tables are allowed in addition to CALS Tables. In other words, both of these tables are valid in DocBook V4.3:
<table frame="sides"> <tgroup cols="1"> <tbody> <row> <entry>1x1 CALS</entry> </row> </tbody> </tgroup> </table> <table frame="border"> <tbody> <tr> <td>1x1 HTML</td> </tr> </tbody> </table>
You can see how quickly this is going to lead to trouble in DTDs or W3C XML Schema: the legal values of the frame attribute and the content models for both table and tbody vary depending on which table you’re using (which you can’t tell until you look inside the table).
What you wind up with in DTDs is something like this:
<!ELEMENT table ((thead?, tfoot?, (tbody|tr+)) | tgroup)>
<!ATTLIST table
frame ( above | all | below | border | bottom | box
| hsides | lhs | none | rhs | sides | top
| topbot | void | vsides) #IMPLIED
>
<!ELEMENT tbody (tr+ | row+)>
That successfully validates both of the tables shown above, unfortunately it also successfully validates gibberish like this:
<table frame="border"> <tbody> <row> <entry>1x1 BROKEN</entry> </row> </tbody> </table>
Which is either a CALS table with an incorrect frame attribute or an HTML table with an incorrect tbody. Larger tables can go awry in even more unintelligible ways.
RELAX NG allows us to specify each model appropriately and then select a choice between them, as seen the section called “Pattern Matching”:
table = html.table | cals.table
html.table =
element table {
attribute frame {
"void"
| "above"
| "below"
| "hsides"
| "vsides"
| "lhs"
| "rhs"
| "box"
| "border" }?,
((html.thead?, html.tfoot?, html.tbody) | html.tr)
}
html.tbody =
element tbody { html.tr+ }
cals.table =
element table {
attribute frame {
"all"
| "bottom"
| "none"
| "sides"
| "top"
| "topbot" }?,
cals.tgroup
}
cals.tbody =
element tbody { cals.row+ }
Even though both “html.table” and “cals.table” match an element named table, each one matches only valid tables of their respective kinds.
The ability to specify units of structure independently and then easily and simply combine them in meaningful ways greatly reduces the complexity of customization without sacrificing important constraints.
Many schemas have a lot of data types and benefit substantially from the additional datatyping constraints of RELAX NG and W3C XML Schemas.
DocBook isn’t really like that. There are a few attributes that are clearly numeric (such as the number of columns in a table), but the only other data types that arise are dates.
In DocBook NG “Bourbon”, the content of date and pubdate elements are constrained to be dates (specifically, date, dateTime, gYearMonth, or gYear).
The decision to require a specific date format in an authoring schema is a little bit controversial. Certainly, some authors want to be able to provide dates using a specific locale (“18 avril 2004,” for example). But requiring a standard format does give processing applications more opportunity to adjust dates to the desired locale.
Grammar based validation technologies (like RELAX NG) and rule based validation technologies (like Schematron) are naturally complimentary. Mixing them allows us to play to the strengths of each without stretching either to enforce constraints that they aren’t readily designed to enforce.
For example, DocBook NG requires that the root element of a document have an explicit version attribute. Because there are a great many elements that can be root elements in DocBook, and because they can almost all appear as descendents of a root element as well, it would be tedious to express this constraint in RELAX NG. But it would be easy in a rule-based schema language.
RELAX NG allows patterns to have additional annotations. Placing Schematron rules in the annotations provides a way of enforcing additional constraints, as shown in Example 7, “Expressing Constraints with Schematron Annotations”.
Example 7. Expressing Constraints with Schematron Annotations
db.book =
[
s:rule [
context = "/db:book"
s:assert [
test = "@version"
"The root element must have a version attribute."
]
]
]
element book {
book.attlist,
book.info,
(navigation.components | components | divisions)+
}
However, relying on an auxilliary validation language imposes costs, both in terms of complexity and interoperability. The complexity cost arises because complete validation now requires two schema languages and (at least conceptually) two validation processes. In practice, there are RELAX NG validators that provide built-in Schematron support.
The complexity is fairly easy to understand and if we accept that writing schemas is a specialized skill that most users will never need to master, we can probably justify it.
The interoperability cost isn’t as easy to understand. The most obvious danger is that some users will only perform the RELAX NG validation and not the Schematron validation. There will be two different levels of “validation” out there and if the number of documents in the difference between these two sets is large, interoperability will be hampered.
In short Schematron constraints look like a good idea, but they might not be. It certainly seems wise to try to minimize the severity of the kinds of errors that the Schematron constraints detect.
At the moment Schematron rules enforce the following constraints:
-
The root element must have a version attribute.
-
Sidebar must not occur in the descendants of sidebar.
-
Footnote must not occur in the descendants of footnote.
-
Admonitions (warning, note, etc.) must not occur in the descendants of an admonition.
-
The number of seg elements must be the same as the number of segtitle elements in the parent segmentedlist.
-
The linkend attribute on synopfragmentref must point to a synopfragment.
-
The linkend attribute on footnoteref must point to a footnote.
-
The otherterm attribute on glosssee must point to a glossentry.
-
The otherterm attribute on glossseealso must point to a glossentry.
-
The linkend attribute on firstterm must point to a glossentry.
-
The linkend attribute on glossterm must point to a glossentry.
Many of the features discussed so far contribute to the ease with which RELAX NG grammars can be customized. RELAX NG provides simple and easy mechanisms for extending or redefining patterns and is able to combine patterns, even patterns that are ambiguous, in the correct way. Defining a pattern as notAllowed allows customizers to completely remove an element or class of elements.
Conversly, writing effective DTD customization layers is a black art requiring not only a deep understanding of the rules for parameter entity definition and expansion but also a complete understanding of the parameter entity structure of DocBook.
Example Example 8, “Removing Procedures from DocBook XML V4.3” shows a customization layer that removes procedures from DocBook. It simply shouldn’t be that hard.
Example 8. Removing Procedures from DocBook XML V4.3
<!-- DocBook XML V4.3 No Procedures Subset -->
<!ENTITY % ebnf.block.hook "">
<!ENTITY % local.compound.class "">
<!ENTITY % compound.class
"msgset|sidebar|qandaset
%ebnf.block.hook;
%local.compound.class;">
<!ENTITY % procedure.content.module "IGNORE">
<!ENTITY % task.content.module "IGNORE">
<!ENTITY % sidebar.element "IGNORE">
<!ENTITY % qandaset.element "IGNORE">
<!ENTITY % qandadiv.element "IGNORE">
<!ENTITY % question.element "IGNORE">
<!ENTITY % answer.element "IGNORE">
<!ENTITY % revdescription.element "IGNORE">
<!ENTITY % caution.element "IGNORE">
<!ENTITY % important.element "IGNORE">
<!ENTITY % note.element "IGNORE">
<!ENTITY % tip.element "IGNORE">
<!ENTITY % warning.element "IGNORE">
<!ENTITY % docbook.dtd PUBLIC "-//OASIS//DTD DocBook XML V4.3//EN"
"http://docbook.org/xml/4.3/docbookx.dtd">
%docbook.dtd;
<!ENTITY % my.sidebar.mix
"%list.class; |%admon.class;
|%linespecific.class; |%synop.class;
|%para.class; |%informal.class;
|%formal.class;
|%genobj.class;
|%ndxterm.class; |beginpage
%local.sidebar.mix;">
<!ELEMENT sidebar (sidebarinfo?,
(%formalobject.title.content;)?,
(%my.sidebar.mix;)+)>
<!ENTITY % my.qandaset.mix
"%list.class; |%admon.class;
|%linespecific.class; |%synop.class;
|%para.class; |%informal.class;
|%formal.class;
|%genobj.class;
|%ndxterm.class;
%local.qandaset.mix;">
<!ELEMENT qandaset (blockinfo?, (%formalobject.title.content;)?,
(%my.qandaset.mix;)*,
(qandadiv+|qandaentry+))>
<!ELEMENT qandadiv (blockinfo?, (%formalobject.title.content;)?,
(%my.qandaset.mix;)*,
(qandadiv+|qandaentry+))>
<!ELEMENT question (label?, (%my.qandaset.mix;)+)>
<!ELEMENT answer (label?, (%my.qandaset.mix;)*, qandaentry*)>
<!ENTITY % my.revdescription.mix
"%list.class; |%admon.class;
|%linespecific.class; |%synop.class;
|%para.class; |%informal.class;
|%formal.class;
|%genobj.class;
|%ndxterm.class;
%local.revdescription.mix;">
<!ELEMENT revdescription ((%my.revdescription.mix;)+)>
<!ENTITY % my.admon.mix
"%list.class;
|%linespecific.class; |%synop.class;
|%para.class; |%informal.class;
|%formal.class; |sidebar
|anchor|bridgehead|remark
|%ndxterm.class; |beginpage
%local.admon.mix;">
<!ELEMENT caution (title?, (%my.admon.mix;)+)
%admon.exclusion;>
<!ELEMENT important (title?, (%my.admon.mix;)+)
%admon.exclusion;>
<!ELEMENT note (title?, (%my.admon.mix;)+)
%admon.exclusion;>
<!ELEMENT tip (title?, (%my.admon.mix;)+)
%admon.exclusion;>
<!ELEMENT warning (title?, (%my.admon.mix;)+)
%admon.exclusion;>
<!-- EOF -->
The same effect can be achieved in the RELAX NG schema almost trivially:
Example 9. Removing Procedures from DocBook NG “Bourbon”
# DocBook NG "Bourbon" No Procedures Subset
namespace db = "http://docbook.org/docbook-ng"
default namespace = "http://docbook.org/docbook-ng"
include "docbook.rnc" {
db.procedure = notAllowed
}
# EOF
Of course, indescriminate use of notAllowed can have consequences. If any of the required children of an element are made not allowed, then that element is also effectively not allowed.
Adding new elements to DocBook NG is just as easy. For example, the customization layer in Example 10, “Adding Exercies to DocBook NG “Bourbon”” adds a new block-level element “exercise” to DocBook:
Example 10. Adding Exercies to DocBook NG “Bourbon”
# DocBook NG "Bourbon" Exercises Extension
namespace db = "http://docbook.org/docbook-ng"
default namespace = "http://docbook.org/docbook-ng"
include "docbook.rnc" {
extension.blocks |= exercise
}
exercise = element exercise { db.title, all.blocks+ }
# EOF
Most customizations that were very tricky with the DTD version of DocBook are straightforward with RELAX NG.
As a practical matter, converting existing DocBook XML documents to DocBook NG by hand would be tedious. Luckily this is just the sort of XML-to-XML transformation at which XSLT excels.
Indeed the stylesheet to perform this conversion is only about 1000 lines long and consists roughly 45 templates. It successfully converts all but eleven of the standard test documents distributed by the DocBook Open Repository. That’s a success rate of more than 94%.
The tests which do not pass are either too complex to convert without intervention or are a little bit pathological:
A cmdsynopsis inside a glossterm
A methodsynopsis inside a variablelist term
An olink element using targetdocent.
Old-style toc markup.
The pathalogical examples, such as putting synopses in elements that are supposed to be inlines, demonstrate that the existing parameter entity content models are sometimes wrong. That shouldn’t be allowed.
The requirement to express DocBook NG in a DTD or W3C XML Schema is essentially the same as the requirement to remove co-constraints, multiple top-level definitions for the same element, and other features that those languages do not support.
The trang converter does an excellent job of boiling DocBook NG down into a W3C XML Schema.
Getting to a DTD is much, much harder. In fact, it isn’t obvious that it can be done. There are some hooks in the schema (such as declarative annotations of attributes that express co-constraints) that may eventually allow a converter to do a better job.
For the moment, the DTD is created by expanding and flattening the content models and reconstituting a DTD From those fragments. This results in a DTD that appears to validate roughly the same grammar (modulo all the constraints that it is unequipt to handle). But there’s no formal framework from which to derive any deep confidence that it is correct. The resulting DTD is also completely devoide of parameter entities: it’s a flat, uncustomizable monolith.
To the extent that it’s going to be possible to apply customizations at the RELAX NG level and regenerate the DTD, this may not be a problem. But it is, at the very least, sub-optimal.
The techniques outlined here have enabled the creation of a DocBook RELAX NG Schema that satisfies the redesign goals to a large extent. DocBook NG “Bourbon”, looks and feels like DocBook while at the same time having simpler, more logical content models and better contraints. The RELAX NG grammar is also demonstrably easier to customize, at least for those applications that can use the RELAX NG grammar directly.
It will undoubtably take several more iterations to arrive at a schema for which there is a consensus that it represents “DocBook,” but the distance from here to there seems much shorter than intuition might have suggested.
DocBook NG is the first DocBook schema in recent history with fewer elements than it’s predecessor. DocBook NG defines only 356 elements. If patterns are considered roughly equivalent to parameter entities, it has a lot fewer of those too: only 1,701.
A natural question to ask is, how many of these goals could have been achieved with a different grammar-based schema language. (Almost any constraint can be expressed with a rules-based schema language, but it isn’t clear that maintaining the set of rules that would be necessary to enforce all of the constraints would actually be a practical approach.)
The existing DocBook DTD provides strong evidence that beyond a certain scale, a DTD-based approach becomes unweildy. While it might be possible to refactor the parameter entities in DocBook to achieve better constraints, such a refactoring would not overcome the limitations inherent in parameter entities or DTD validation. Maintaining or customizing a large, seriously parameterized DTD is never going to be a straightforward task.
Some of the goals for DocBook NG could be achieved with W3C XML Schema. Certainly there are mechanisms in W3C XML Schema that would help overcome some of the limitations of DTDs. Inheritance, perhaps, local element declarations, and substitution groups would provide facilities to untangle some of the parameter entity mess.
Using xs:redefine with model groups would also provide a way to modify the named model groups in the schema, at least in those environments were redefinition is supported.
But at the end of the day, there would still some serious impedence mismatches:
-
One of the abstractions behind W3C XML Schema is that an XML document is a tree of typed objects. In a schema where nearly half the elements are mixed content and there is great variablility at almost every level of the hierarchy, this does not seem to be a very suitable abstraction.
-
W3C XML Schema retains the determinism rules of XML DTDs. In order to provide a rich extensibility framework in the face of this constraint, the initial design must be made much more complex. This complexity hampers understanding, maintainance and ultimately customization.
-
Local element declarations intefere with customizability. In order to change the declaration of a locally declared element, the declaration for its parent must be changed. Obviously, if local element declarations are nested, this problem cascades up the heirarchy.
-
The inability to express co-constraints would prevent any progress from being made in those areas.
The DocBook NG design has been very directly influenced by the decision to implement it in RELAX NG. For those less familiar with RELAX NG, this section summarizes very informally some of the important features of RELAX NG.
RELAX NG is normatively defined with an XML syntax. A typical example looks like this:
<element name="orgname" xmlns="http://relaxng.org/ns/structure/1.0"> <text/> </element>
To make hand authoring easier, RELAX NG can also be described in a compact syntax. The compact syntax equivalent of the preceding construction is:
element orgname { text }
The two syntaxes are isomorphic: that is, everything that can be represented in the element syntax can also be represented in the compact syntax and vice versa.
This makes the selection of syntax largely one of personal choice. The examples in this paper use the RELAX NG Compact Syntax because it generally makes the examples shorter.
In the discussion that follows, it will be helpful to recall how validation works in RELAX NG.
A RELAX NG grammar defines a set of patterns. At the leaves, there are patterns that match individual text nodes, elements, or attributes. Patterns can be combined with “and” and “or” connectors and grouped into ordered or unordered sequences.
Validation begins with the specially identified “start” pattern and asks the question, does this document match the start pattern? A few examples will help.
Here is a simple pattern that matches an element called “orgname” that contains text.
element orgname { text }
Patterns can also be named. Pattern names, like variable names in a program, are irrelevant; often element and attribute patterns are named after the element or attribute they match, but they don’t have to be.
Here is another pattern, named “class”, that matches an optional attribute called “class” if and only if it has one of the listed values:
class = attribute class {
"consortium"
| "corporation"
| "informal"
| "nonprofit" }?
The vertical bars indicate an “or” choice and the question mark makes the attribute optional.
The next example is a little more complicated. It matches two attributes simultaneously “class” if and only if it has the value “other” and “otherclass” that contains text.
otherclass = attribute class { "other" }
& attribute otherclass { text }
The ampersand connector indicates an “and” choice; both of the attributes must be present but their order is irrelevant. Since attribute order is always irrelevant, there’s no practical difference between an “and” connector and a simple sequence connector (the comma) in this case.
Finally, let’s look at how the patterns can be combined to create an “orgname” pattern:
orgname =
element orgname {
(class | otherclass),
text
}
What does this match? It matches an element named “orgname” that matches a sequence consisting of two patterns. The first pattern matches either the “class” pattern or the “otherclass” pattern. The second pattern matches text. The class pattern matches an optional attribute named “class” that contains text. The otherclass pattern matches a required attribute named “class” that has the value “other” and a required attribute named “otherclass” that contains text.
What does this mean in practice? It means that our “orgname” pattern matches all of the following:
<orgname>IDEAlliance</orgname> <orgname class="consortium">OASIS</orgname> <orgname class="other" otherclass="plc">Example Corp.</orgname>
It does not match:
<orgname class="other">IDEAlliance</orgname> <orgname otherclass="llc">Example Corp.</orgname>
Note that this expresses a useful constraint that can’t be expressed in either DTDs or W3C XML Schema.
RELAX NG validation works by finding pattern matches. This is a non-deterministic process. Bluntly: a pattern matches if it matches. The example above matched on attributes, but it could equally well have matched on nested element structure. The RELAX NG validator is allowed arbitrary look ahead in determining if a pattern matches.
Non-determinism gives RELAX NG much more expressive power then either DTDs or W3C XML Schema. The previous section highlighted a simple problem of co-constraints that is easy to solve in RELAX NG. This same power will be used to solve a much trickier problem in the section called “Untangling Tables”.
It’s worth pointing out that non-determinism is not a universally good thing. There are application domains in which it would be very bad indeed.
Consider, for example, an application that was using XML to serialize Java objects sent over the net. The application receiving this XML might want to know, as soon as it had seen the start tag, what kind of object it was going to need to allocate for the incoming data.
In RELAX NG, you might not know the type until you’d seen some descendent a half a gigabyte further down the stream. That could be…inconvenient.
Worse, you might never know the type. Consider this pattern:
element po {
(element poType { text }
| element poType { xsd:integer }
}
If it matches this element,
<po><poType>3</poType></po>
Is the type a string or an integer? Yes. It is either a string or an integer and RELAX NG validation doesn’t tell you which one.
There’s also the question of performance. If you really do have to wait until you’ve seen half a gigabyte of data before you can decide what type something is, that could be bad, right?
The fact is, yes it could. But the open question is, does this happen in the real world? Just because you can write non-deterministic schemas that require arbitrary lookahead to decide that they can’t decide what type something is doesn’t mean you have to.
For applications like DocBook which contain a lot of human authored text, the tradeoff seems clear to me: non-determinism simplifies the schema, allows us to express tighter constraints, and does not interfere with the sorts of processes that seem most likely to be used with the documents.
[RELAX NG Compact Syntax] James Clark, editor. RELAX NG Compact Syntax (Committee Specification). OASIS. 2002.
[RELAX NG Tutorial] James Clark, MURATA Makoto, editors. RELAX NG Tutorial (Committee Specification). OASIS. 2001.
[Schematron] Rick Jelliffe, editor. The Schematron Assertion Language 1.5. Rick Jelliffe and Academia Sinica Computing Centre. 2001, 2002.
[DocBook: TDG (Special Edition)] Norman Walsh and Leonard Meullner. DocBook: The Definitive Guide (Special Edition). 2004.