07 Aug 2003
04 - 08 August, 2003
Montreal, Quebec, Canada
Copyright © 2003 Sun Microsystems, Inc.
Abstract
RDF is a powerful, standard way to represent metadata. XSLT is a powerful, standard way to transform documents. Unfortunately, it isn't particularly easy to transform RDF graphs with XSLT.
This paper describes a new strategy for making RDF amenable to XSLT processing. It introduces RDF Twig, set of extension functions for Saxon and Xalan that provide a flexible methodology for accessing RDF graphs from XSLT.
$Id: rdftwig.xml,v 1.5 2003/08/19 12:20:08 ndw Exp $
Table of Contents
As a tool for manipulating XML documents, few would dispute the utility and widespread application of [XSLT]. As a technology for manipulating RDF documents, however, even though they can be represented in XML, it is a source of considerable frustration. This became eminently clear at a conference last year at which the speakers at nearly ever RDF-related talk I attended bemoaned the lack of a standard serialization for RDF, often specifically to make it more amenable to XSLT processing.
In this paper, I explore an alternative solution to the problem of processing RDF with XSLT and describe an open source toolkit which implements that solution.
The syntactic markup of XML is designed to describe trees. A document such as Figure 1, “An XML Document” has a natural tree representation:
More significantly, the document in Figure 1, “An XML Document” has exactly one tree representation, the one shown in Figure 2, “The XML Tree”.

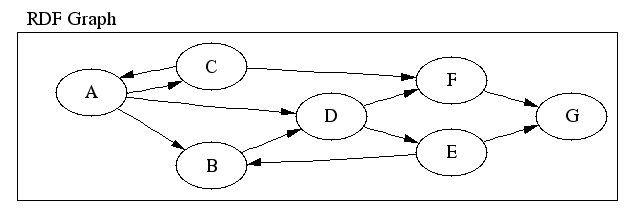
A collection of RDF statements, on the other hand, cannot generally be represented as a tree. It can only be represented as a directed graph. An RDF graph is not required to be either acyclic or even connected. Consider the small collection of statements in Figure 3, “A Collection of RDF Statements”.
@prefix : <http://example.com/graph#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . # RDF Schema :Node a rdfs:Class . :linksTo a rdfs:Property . :label a rdfs:Property . # Nodes :D a :Node . :E a :Node . :F a :Node . :G a :Node . :A :linksTo :C . :C :linksTo :A . :D :linksTo :E . :A :label "A" . :B :label "B" . :E :label "E" . :F :label "F" . :G :label "G" . :A :linksTo :B . :E :linksTo :G . :B :linksTo :D . :A :linksTo :D . :D :linksTo :F . :E :linksTo :B . :F :linksTo :G . :C :linksTo :F . :A a :Node . :B a :Node . :C a :Node . :C :label "C" . :D :label "D" .
Figure 3. A Collection of RDF Statements
These statements illustrate several points:
-
They are presented in [N3], a defacto standard non-XML syntax for RDF graphs, to emphasize the fact that RDF is a model that can be represented without any XML at all.
-
They are presented in a randomized order to emphasize that the order of statements is insignificant: each statement stands on its own. The statement “:B :linksTo :D” asserts that the “:linksTo” property of the node “:B” has as its value the node “:D” no matter where its said or what else might be said about the nodes “:B” and “:D”.
-
The nodes and relationships described by these statements do not form a tree.
This last point can most easily be seen by examining a visual representation of the nodes described by the RDF statements, as shown in Figure 4, “The RDF Graph”.
Obviously RDF graphs can be serialized as XML. These serialized forms, because they're in XML, must be amenable to processing with XSLT. Why isn't that enough?
When a graph is serialized, some of the edges in the graph can be represented in the structure of the XML. Other edges, ones that cause the graph not to conform to the constraints of a tree, must be represented in some other way.
For example, consider this fragment of an XML serialization of the RDF statements in Figure 3, “A Collection of RDF Statements”:
<Node rdf:about="http://example.com/graph#A">
<label>A</label>
<linksTo rdf:resource="http://example.com/graph#B"/>
<linksTo rdf:resource="http://example.com/graph#C"/>
<linksTo rdf:resource="http://example.com/graph#D"/>
</Node>
The value of the label property is represented directly in the children of the Node. In XPath terms, if the node “A” is the context node, then “child::label/node()” gives the value of the label property.
The values of the linksTo properties are represented indirectly through an rdf:resource attribute. In order to get at the actual values, you must find the nodes labelled with rdf:about attributes that have the corresponding values. In particular, in XPath terms, it is not the case that “child::linksTo/node()” returns the values of the properties.
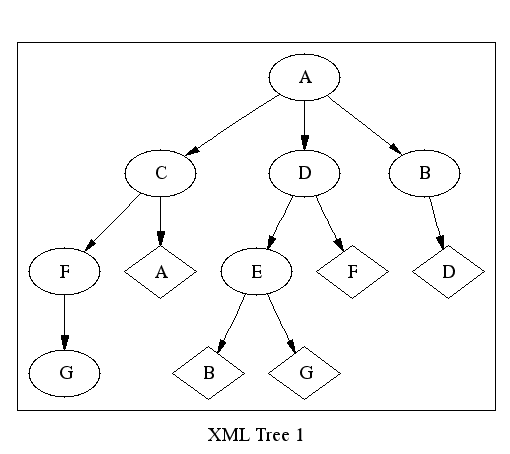
Figure 5, “A Tree View of the RDF Graph” shows one tree representation for the RDF graph in Figure 4, “The RDF Graph”. In this tree, the nodes show as ovals, and the edges between them, are represented directly. The edges that lead to nodes shown in diamonds can't be represented directly; they must be represented with links or some other mechanism.
When the value of a property is another resource (or node) in the graph, as opposed to a literal value, the serialization is constrained not only to make a tree but also to preserve the identity of the node. As a result, the trees produced by actual RDF serialization in XML don't look quite like this one, but the distinctions aren't important here.
Tools like XSLT are designed to operate over trees. They have a processing model that's designed to take advantage of the structure of trees: that every node has one parent, that exactly one node has no parent, that siblings are ordered, and other architectural features of trees that simply do not apply to more general graphs.
What this means in practical terms is that you get an (essentially arbitrary) division of edges into two classes: those that are expressed directly in the XML and those that are represented in another way.
To make this concrete, consider node “C” in Figure 5, “A Tree View of the RDF Graph”. In the RDF graph, nodes “A” and “F” are equally reachable from “C”; they are indistinguishable from the point of view of their connectedness in the graph. However, in the tree form, the two nodes are not equally reachable. One of them, “F” in this case, is avialable directly as a child of “C” but the other is not.
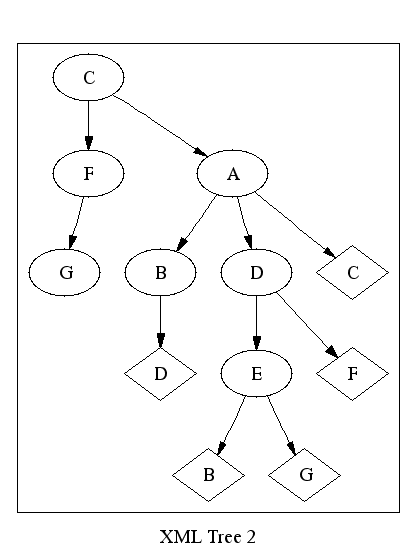
This problem is compounded by the fact that there is no “right” way to choose which edges should be represented in the tree and which should be represented in another way. For example, Figure 6, “Another Tree View of the RDF Graph” shows an equally “right” tree representation for the RDF graph in Figure 4, “The RDF Graph”.
In the quest for a “standard serialization”, the fact that different views of the graph are equally valid is a frustrating problem. But in the context of tackling any particular task, it can be a great advantage.
This is one of the key insights that lead to the development of RDF Twig: in the course of solving a transformation problem, it can be very useful to look at a graph from different perspectives.
Suppose, for example, that you're modelling some complex engineering project with RDF. You have a graph that contains software engineers, technical writers, tasks, subtasks, milestones, and deliverables and a myriad of relationships between them.
In the course of generating some kind of report, it can be very handy to pick different views of the graph: for some parts of the report, it's most efficient to root the view at an engineer and treat the tasks and subtasks she's responsible for as descendants; for other parts of the report, it's most efficient to root the view at a task and treat the engineers and subtasks as descendents.
The ability to dynamically generate these views allows you to generate efficient, understandable algorithms for the various tasks you need to apply to an RDF graph.
To keep the examples smaller, let's consider a simpler RDF graph such as the one shown in Figure 7, “A Small RDF Graph”.

There are two obvious ways to construct a tree from this graph: breadth first and depth first.
To construct a breadth first tree, you process each node that is directly connected to the current node before you process any nodes that are indirectly connected.
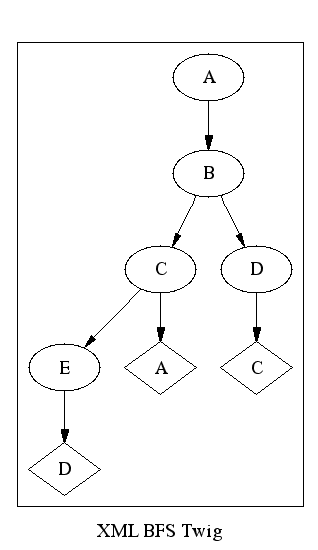
To preserve the identity of nodes in the original RDF graph, and to prevent recursion, are placed directly in the tree only when they are first encountered. If they occur more than once, they are added simply as links.
In RDF Twig, this is called a “twig” because it's the shallowest breadth first tree that contains all the nodes.
To construct a depth first tree, you process each node and all of its descendants before you process any other node.
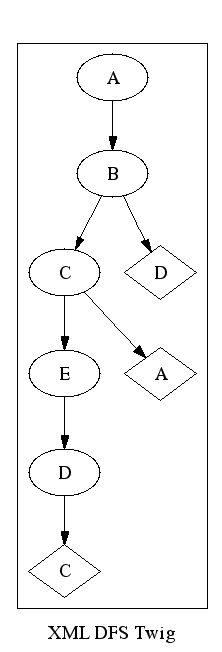
As with the breadth first tree, nodes are placed directly in the tree only when they are first encountered. If they occur more than once, they are added simply as links.
In RDF Twig, this is also called a “twig” because it's the shallowest depth-first tree that contains all the nodes.
Another key insight in the development of RDF Twig was that the purpose of generating trees in this context is to make processing the graph easier, not to accurately model the underlying RDF.
An RDF serialization, intended to be consumed later to rebuild the underlying graph, must carefully preserve node identity and other properties of the graph. RDF Twig generates trees, but they do not have to be useful serializations of the RDF. A couple of examples will help clarify this point.
Once we've abandoned the need to preserve node identity, we can build much deeper graphs, allowing nodes to occur more than once. In order to prevent infinite recursion, it is still sometimes necessary to add nodes as links.
The deep tree for Figure 7, “A Small RDF Graph” is shown in Figure 10, “A Deep Tree”. In the context of RDF Twig, this is called a deep breadth first tree. That the breadth first and depth first “deep trees” are identical is left as an exercise for the reader.
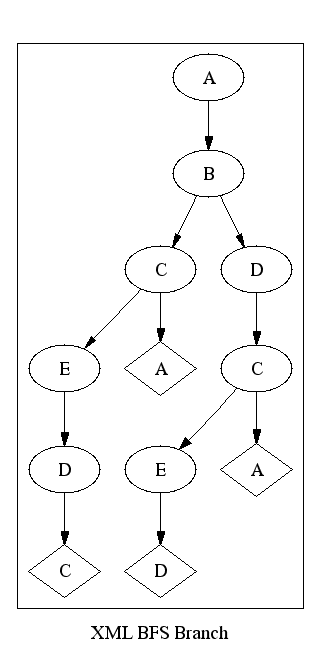
In this tree we see that nodes are repeated everytime they are encountered, unless they already occur as a direct ancestor.
In RDF Twig, this is called a “branch” because, well, because it's bigger than a twig.
RDF Twig is a small set of XSLT extension functions designed to allow a stylesheet to access RDF statements in a repository as a set of dynamically constructed branches, twigs, and leaves.
The present implementation is in Java for easy integration into the Java Web Services Developer Pack and related technologies.
RDF Twig provides extension functions for the [Saxon] and [Xalan] processors. It operates over the [Jena] repository.
RDF Twig exposes a number of extension functions. Unless otherwise noted, these functions return external objects, opaque to XSLT, that can be used as arguments to other RDF Twig functions. The summary provided here is intended to give you a feel for the API, more complete details can be found in the JavaDoc.
| load |
Loads an RDF model into memory. |
| resource |
Returns a resource from the model. |
| twig |
Returns an element (an XSLT input document) that is the root of a breadth first twig beginning at the specified resource. |
| dftwig |
Returns an element (an XSLT input document) that is the root of a depth first twig beginning at the specified resource. |
| branch |
Returns an element (an XSLT input document) that is the root of a branch beginning at the specified resource. |
| leaf |
Returns an element (an XSLT input document) that is the root of a leaf beginning at the specified resource. |
Most of these functions are available in several forms, allowing different combinations of models, input nodes, and resources.
Building real applications with RDF Twig quickly revealed that it would be a lot more useful if it provided hooks to perform a small set of logical operations on the RDF graph. Consequently, RDF Twig also provides these extension functions:
| property |
Constructs an RDF property (for use in subsequent queries). |
| find |
Return a set of all the resources in the model that satisfy a particular condition (such as having a given property or a given value for a particular property). |
| get |
Return a set of all the resources in the model that are the value of a specified property on a resource. |
| filter |
Extract from a set of resources all those that have a particular property or a particular property with a specified value. |
| filterNot |
Extract from a set of resources all those that do not have a particular property or do not have a particular property with a specified value. |
| union |
Returns the union of two sets of resources. |
| intersection |
Returns the intersection of two sets of resources. |
| difference |
Returns the difference between two sets of resources. |
It's possible to accomplish a great deal with the primitive operations provided by the extension functions, but it is not always convenient. For complex operations, it is often easier to construct and evaluate a query directly. RDFTwig provides an extension element to expose Jena's RDQL query engine.
The rdql element has two attributes: model and return. The body of the element is simply the text of the RDQL query. For convenience, it is treated as an attribute value template, allowing the author to construct RDQL queries from XPath expressions.
The model attribute identifies the RDF model to query and return names the “variable” from the RDQL expression that will be returned.
For example, consider one of the queries from the Jena RDQL documentation, as it might be used in a stylesheet:
<rq:rdql return="a"> SELECT ?a, ?b WHERE (?a, <http://somewhere/pred1>, ?b) AND ?b < 5 </rq:rdql>
This extension element evaluates the query (over the default model) and returns all of the resources selected by “?a” in the expression.
The results are returned as a set of twig:result elements. If the query results are nodes or resources, each result element will have an rdf:resource attribute. If the query selects literals, they will appear as the content of the result elements.
Accessing the results in XSLT 1.0 will require access to the EXSL node-set extension function, or a proprietary equivalent. The extension element mechanism requires results to be returned as a result tree fragment.
Returning to the larger graph in Figure 4, “The RDF Graph”, let's make a tree starting at the node “D”.
Our stylesheet begins by declaring the appropriate extension namespace and the result set prefix:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"
xmlns:rt="http://nwalsh.com/xslt/ext/com.nwalsh.xslt.saxon.RDFTwig"
xmlns:twig="http://nwalsh.com/xmlns/rdftwig#"
xmlns:g="http://example.com/graph#"
exclude-result-prefixes="rt">
Next we must load a model:
<xsl:template match="/">
<!-- load the model -->
<xsl:variable name="model"
select="rt:load('diagrams/bgraph.rdf')"/>
The first model loaded is treated as the default and can be omitted from other function calls. If you load multiple models, you have to pass the secondary models explicitly to each function. In this example, we take advantage of the fact that we're using the default model.
In order to search for a property value, we must construct a property:
<!-- construct a label property -->
<xsl:variable name="label"
select="rt:property('http://example.com/graph#', 'label')"/>
Now we can use the find function to search for nodes that have the literal “D” as the value of their label property:
<!-- find the node(s) labelled "D" -->
<xsl:variable name="findResults"
select="rt:find($label, 'D')"/>
Finally, we can view the result set as a tree and extract the results:
<!-- build a twig from the result set and grab the result -->
<xsl:variable name="tree"
select="rt:twig($findResults)/twig:result"/>
At this point, $tree contains an XML document that can be queried and transformed with XSLT like any other input document. In particular, we can copy it to the result tree:
<!-- output the tree --> <xsl:copy-of select="$tree"/> </xsl:template> </xsl:stylesheet>
The resulting document is shown in Figure 12, “The Extracted Tree”.
<?xml version="1.0" encoding="utf-8"?>
<ns1:result xmlns:ns1="http://nwalsh.com/xmlns/rdftwig#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ns2="http://example.com/graph#"
rdf:about="http://example.com/graph#D">
<rdf:type rdf:about="http://example.com/graph#Node">
<rdf:type rdf:about="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:type>
<ns2:label>D</ns2:label>
<ns2:linksTo rdf:about="http://example.com/graph#E">
<rdf:type rdf:resource="http://example.com/graph#Node"/>
<ns2:label>E</ns2:label>
<ns2:linksTo rdf:about="http://example.com/graph#B">
<rdf:type rdf:resource="http://example.com/graph#Node"/>
<ns2:label>B</ns2:label>
<ns2:linksTo rdf:resource="http://example.com/graph#D"/>
</ns2:linksTo>
<ns2:linksTo rdf:about="http://example.com/graph#G">
<rdf:type rdf:resource="http://example.com/graph#Node"/>
<ns2:label>G</ns2:label>
</ns2:linksTo>
</ns2:linksTo>
<ns2:linksTo rdf:about="http://example.com/graph#F">
<rdf:type rdf:resource="http://example.com/graph#Node"/>
<ns2:label>F</ns2:label>
<ns2:linksTo rdf:resource="http://example.com/graph#G"/>
</ns2:linksTo>
</ns1:result>
Figure 12. The Extracted Tree
This is not a very attractive piece of XML, serializing has forced the processor to choose arbitrary namespace prefixes, but serialization is not the typical use for RDF Twig trees.
Instead, note how we've exposed information in a very XSLT-friendly way. If you wanted to calculate all the nodes reachable from “D” in the original RDF graph, you'd have to write a fairly hairy set of templates. To get that information from this RDF Twig tree, you need no more than the simple XPath expression “$tree//g:linksTo/g:label”.
RDF Twig can be used iteratively to explore the graph. Suppose, for example, that you wanted to find information about the node “E” reachable from “D”. Now that you have “$tree” in hand, you can find that node easily:
<xsl:variable name="E" select="$tree/g:linksTo[g:label='E']"/>
The RDF Twig functions can take nodes as input parameters, so it's not necessary to use a query to find “E”, you can simply grab the result node that represents it. Then getting information about it is straightforward:
<xsl:variable name="Etree" select="rt:twig($E)"/>
Additional arguments allow you to tailor the results in a variety of ways, such as setting the maximum depth of the returned tree.
RDF is a powerful, standard way to represent metadata of arbitrary complexity. XSLT is a powerful, standard way to transform trees. RDF Twig brings these two worlds together, giving XSLT a mechanism for manipulating RDF graphs by extracting arbitrary trees.
A. The RDF Twig Software
RDF Twig is a SourceForge project. You will find additional documentation, including the RDF Twig JavaDocs, at the project homepage.
Jena is a project of the Advanced Research lab at HP. I have no formal connection with them, but RDF Twig wouldn't exist without Jena and I'd like to thank the HP Semantic Web folks publically for a very practical toolkit. The current RDF Twig implementation is built on top of the Jena V1.6.x store. As Jena V2 stabalizes, RDF Twig will most likely migrate to the new API.
[Xalan] Apache Software Foundation. Xalan-Java Version 2.
[N3] Tim Berners-Lee. Primer: Getting into RDF & Semantic Web using N3.
[XSLT] James Clark, editor. XSL Transformations (XSLT) Version 1.0. World Wide Web Consortium, 1999.
[Jena] HP Labs Jena Semantic Web Toolkit.
[Saxon] Michael Kay. SAXON XSLT Processor.